

Date and Time: Tuesday, November 18, 2025 | Current Status: UTC 13:35
Introduction:
When the Internet’s Foundation Stumbles
The modern internet, despite its appearance of seamless global connectivity, relies heavily on a few critical infrastructure providers. Cloudflare, a major provider of Content Delivery Network (CDN) and web security services, experienced a significant global outage on Tuesday, November 18, 2025. This single-point failure sent shockwaves across the digital world, rendering numerous essential services inaccessible for millions of users worldwide.
Among the most high-profile victims of this disruption were X (formerly Twitter), one of the world’s largest social media platforms, and OpenAI’s ChatGPT, the dominant force in the generative Artificial Intelligence (AI) space. The outage once again highlighted the fragility of a centralized web architecture and the immense reliance the global digital economy places on companies like Cloudflare.
This detailed report offers a timely and in-depth analysis of the outage, covering the timeline, the nature of the issue, the root cause identified so far, the extent of the global impact, and the ongoing recovery efforts as of the latest updates.
Understanding Cloudflare’s Role in the Internet Ecosystem
To appreciate the scale of the outage, it’s vital to understand Cloudflare’s position. Cloudflare operates as a protective and performance-enhancing layer that sits between the user and the origin server of a website. Its services are critical for maintaining the speed, reliability, and security of millions of online properties.
Key Cloudflare Services Affected by the Outage:
- Content Delivery Network (CDN):
Cloudflare caches (stores copies of) website content across its vast global network of data centers. When a user requests a website, the content is served from the closest location, drastically reducing latency and improving speed.

- DDoS Mitigation and Security:
The company’s primary function is to protect websites from malicious traffic, particularly Distributed Denial of Service (DDoS) attacks, by filtering and absorbing the massive amounts of junk data before it reaches the customer’s servers.

- Web Infrastructure:
Many sites rely on Cloudflare for their fundamental DNS resolution, security challenges (like CAPTCHAs), and API gateway functionality.
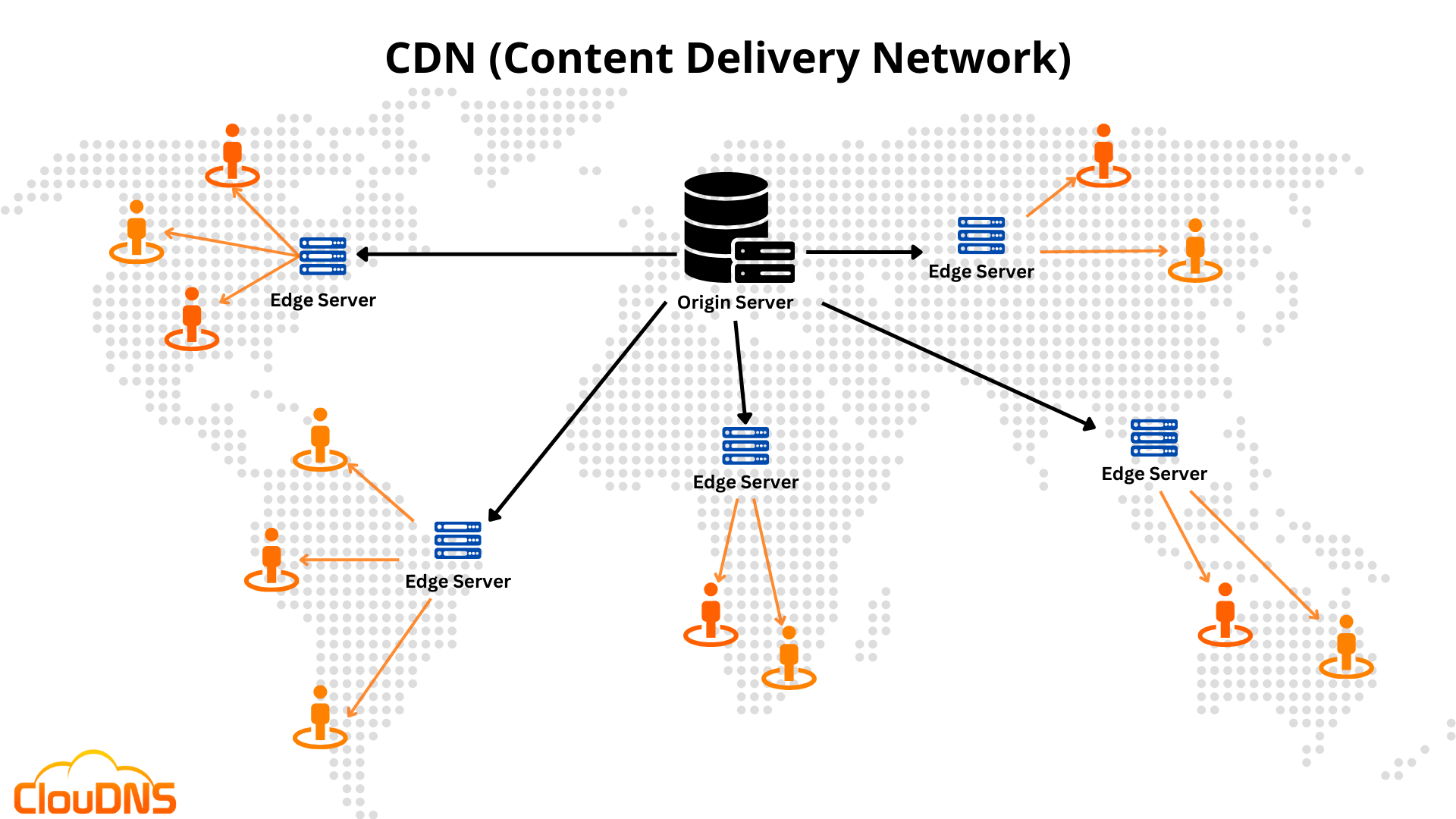


When Cloudflare’s core network experiences a failure, the security and content delivery mechanisms it provides become the point of failure, meaning that even if a customer’s origin server is perfectly fine, users cannot access the site.
The Outage Timeline:
What Happened and When?
The global disruption began abruptly during the mid-morning UTC hours, affecting users simultaneously across Asia, Europe, and the Americas.
The Onset of the Disruption
The first significant reports of service degradation emerged around 11:20 UTC to 12:00 UTC on Tuesday, November 18, 2025 (approximately 7:00 AM Eastern Time in the U.S.).
- Initial Reports: Users attempting to access major sites began receiving Widespread 500 Errors—a clear indication of an internal server issue within the infrastructure layer.
- Cloudflare’s Acknowledgment: Cloudflare quickly confirmed the issue on its official status page, stating: “Cloudflare is aware of, and investigating an issue which impacts multiple customers: Widespread 500 errors, Cloudflare Dashboard and API also failing.” The outage was described as an “internal service degradation.”
- Ironic Failure: Even Downdetector, a popular website used to track outages, was briefly impacted, underscoring the ubiquitous nature of Cloudflare’s network reliance.
User Experience and Error Codes
Unlike a simple website crash, the Cloudflare outage presented specific, system-level errors to end-users:
- HTTP 500 Error: This is the most common error reported, signifying that the Cloudflare server encountered an unexpected condition that prevented it from fulfilling the request.
- Challenge Prompts: Some users saw the message: “Please unblock https://www.google.com/search?q=challenges.cloudflare.com to proceed.” This highly unusual message indicated that the very security and challenge mechanisms designed to protect the websites were malfunctioning and blocking legitimate traffic.


{kind=link}
The Root Cause: Internal Service Degradation
While Cloudflare has yet to release a detailed post-mortem analysis (which is typical for such events), initial statements and observations point toward an internal system fault rather than an external cyberattack like a DDoS event.
- Unusual Traffic Spike:
The official statement confirmed an “unusual spike in traffic” to one of Cloudflare’s internal services beginning around 11:20 UTC. - Cascading Failure:
This spike, the cause of which is currently unknown (but potentially due to a faulty software deployment or a large-scale configuration change), led to a cascading failure within Cloudflare’s architecture. Because Cloudflare’s security, API, and core network functions are tightly integrated, the failure in one internal service quickly overwhelmed others. - Prioritization of Stability:
The immediate steps taken, such as the temporary disabling and then re-enabling of the WARP connection service in certain areas (like London), strongly suggest that Cloudflare’s engineers were performing emergency isolation and configuration rollbacks to restore network health. This action focused on stability by isolating the problematic component.
This incident strongly echoes previous outages experienced by major cloud providers, where a small internal change or an unexpected input load can bring down critical segments of the global internet due to the massive scale and complex interdependencies of these systems.
Global Impact: X, ChatGPT, and Beyond
The vast network of customers relying on Cloudflare meant that the outage’s impact was widespread and multi-sectoral.
The Fallout on Key Platforms
| Platform | Sector | Impact Description |
|---|---|---|
| X (formerly Twitter) | Social Media/News | Widespread inability for users to load posts, access their feed, or post new content. This severely disrupted real-time global communication and news dissemination. |
| ChatGPT (OpenAI) | Artificial Intelligence | The core service, including the ChatGPT interface and the underlying OpenAI API (used by countless developers), was hit. This paralyzed AI-driven research, development, and customer service tools globally. |
| Spotify | Entertainment/Streaming | Users reported being unable to stream music or access the service, disrupting media consumption. |
| League of Legends | Online Gaming | Several large online gaming platforms, including Riot Games’ League of Legends, experienced server issues and connection failures. |
| Canva & Shopify | E-commerce/Productivity | E-commerce sites (Shopify) and online design tools (Canva) suffered errors, directly impacting global business operations and productivity. |
The simultaneous failure of services across completely unrelated sectors—from AI and social media to gaming and e-commerce—served as a stark reminder that they all share a single, underlying infrastructure vulnerability: the reliance on a few concentrated service providers.
Resolution Status and Recovery Efforts
As of the latest update at UTC 13:35 on November 18, 2025, Cloudflare has made significant progress in mitigating the issue, though the incident is not yet fully closed.
Key Recovery Milestones
- Service Recovery Observed:
Cloudflare’s status page transitioned from “Investigating” to confirming that “We are seeing services recover.” This indicates that the initial fixes—likely configuration changes or targeted disabling of the failing components—have been effective in restoring primary network traffic flow. - Error Rates Normalizing:
The company noted that error levels for services like Cloudflare Access and WARP had returned to “pre-incident rates,” suggesting a return to stability in those core functions. WARP access in London, which was disabled as a containment measure, has been re-enabled. - Ongoing High Error Rates:
A caution remains: “customers may continue to observe higher-than-normal error rates as we continue remediation efforts.” This suggests that while core functionality is back online, residual issues, increased latency, or intermittent errors may persist in certain regions or services while engineers perform a full system check and ensure comprehensive stability.
The immediate crisis appears to have passed, but the work of fully stabilizing a network of this scale is complex and time-consuming, necessitating constant monitoring and gradual restoration of all services.
The Broader Implications:
The Peril of Internet Centralization
This Cloudflare outage, following major disruptions from other providers like Amazon Web Services (AWS) in previous months, highlights a fundamental vulnerability in the modern internet structure: centralization.
The Double-Edged Sword of Centralization
| Benefit (Why Companies Use Cloudflare) | Risk (The Outage Lesson) |
|---|---|
| Efficiency and Cost: Outsourcing infrastructure is cheaper and more efficient than building proprietary networks. | Single Point of Failure: One company’s internal mistake can instantly cripple a significant percentage of the world’s most-visited sites. |
| Superior Performance: Highly optimized CDN ensures content delivery is fast globally. | Loss of Resilience: If the protective layer fails, the site goes down regardless of the origin server’s health. |
| Advanced Security: Only centralized providers can afford to block record-breaking DDoS attacks. | Universal Vulnerability: A systemic failure exposes billions of users across all platforms simultaneously. |
The Call for Decentralization and Diversity
The incident serves as a loud warning that companies, especially those critical to global communication and commerce like X and ChatGPT, must seriously consider multi-CDN strategies and greater infrastructure diversity. Relying on a single vendor, no matter how reliable, introduces an unacceptable level of systemic risk. The future stability of the internet may depend on a shift away from over-reliance on a few dominant players toward a more distributed and resilient model.
Conclusion:
A Quick Recovery, A Long-Term Question
The Cloudflare global outage of November 18, 2025, temporarily paralyzed giants like X and ChatGPT, offering a brief but significant glimpse into the potential fragility of the internet’s interconnected systems. While the technical teams at Cloudflare rapidly implemented fixes to bring core services back online within a few hours, the fundamental question about Internet resilience remains.
As the world continues its deep integration with digital platforms and AI tools, ensuring that the underlying infrastructure is robust, diverse, and resistant to single-point failures is not just a technical challenge—it is an economic and social necessity. The post-incident analysis from Cloudflare will be crucial in determining the exact cause and preventing future recurrences, but for now, the internet community is collectively breathing a sigh of relief as services return to normal.
LATEST UPDATE:
UTC 14:57 (Indian Time: 8:27pm)
The problem is now solved after 3 hours….. This was announced by the company. However, the damages caused to many websites by this will not be fixed (or compensated).

(Click notification ![]() for more updates)
for more updates)
By: V.Harishram
”Stay true, bring facts to you”
The problem is now solved after 3 hours….. This was announced within the company. However, the damages caused to many websites by this will not be fixed (or compensated)